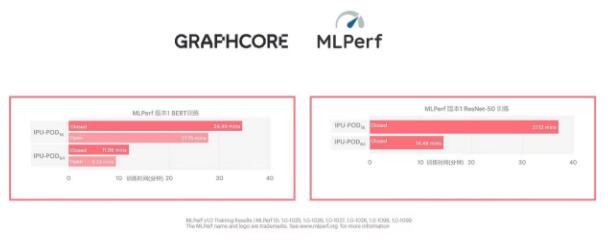
2021年7月1日,Graphcore(拟未科技)正式公布其参与的首次MLPerf™提交结果,Graphcore产品表现优异,AI性能稳居领先地位。MLPerf是AI行业最受认可的比较基准测试。此次测试结果显示,在Graphcore IPU-POD64上,BERT的训练时间只有9分多钟,ResNet-50的训练时间为14.5分钟,AI性能已达超级计算机级别。
MLPerf还对比了市面上的Graphcore系统与NVIDIA的最新产品,结果证实Graphcore在“每美元性能”(Performance-Per-Dollar)指标上稳居领先地位。对客户而言,这项重要的第三方测试确认了Graphcore系统不仅具有新一代AI的优异性能,同时在目前的广泛应用中也表现得更出色。
MLPerf基准测试
对于第一次MLPerf(训练版本1.0)提交,Graphcore选择聚焦在关键图像分类和自然语言处理的应用基准测试类别。MLPerf图像分类基准使用流行的ResNet-50版本1.5模型,在ImageNet数据集上训练,以达到适用于所有提交情况的准确率。对于自然语言处理,使用了BERT-Large模型和选取的一个代表性片段。该片段大约占总训练计算工作负载的10%,并使用维基百科数据集进行训练。Graphcore决定提交使用ResNet-50和BERT的图像分类和自然语言处理,在很大程度上是由客户和潜在客户驱动的,因为这是他们最常用的一些应用和模型。此次在MLPerf测试中的强劲表现,进一步证明了Graphcore系统完全可以满足当今的AI计算要求。
参与测试的两个Graphcore系统,IPU-POD16和IPU-POD64,均已在生产中交付给客户。
· 价格实惠、结构紧凑的5U IPU-POD16系统适用于刚开始构建IPU AI计算能力的企业客户。它由4个1U的IPU-M2000和1个双CPU服务器(dual-CPU server)组成,可以提供4 PetaFLOPS的AI处理能力。
· 纵向扩展的IPU-POD64包含16个IPU-M2000和数量灵活的服务器。Graphcore系统实现了服务器和AI加速器的解耦,因此客户可以根据工作负载指定CPU与IPU的比率。例如,和自然语言处理相比,计算机视觉任务通常对服务器的需求更高。对于MLPerf,IPU-POD64在BERT的提交中使用了1台服务器,在ResNet-50的提交中使用了4台服务器。每台服务器均由2个AMD EPYC™ CPU驱动。
MLPerf测试包含开放分区和封闭分区两个提交分区。封闭分区严格要求提交者使用完全相同的模型实施和优化器方法,包括定义超参数状态和训练时期。开放分区保证和封闭分区完全相同的模型准确性和质量,但支持更灵活的模型实施以促进创新。因此,该分区支持更快的模型实现,更加适应不同的处理器功能和优化器方法。对于像Graphcore IPU这样的创新架构,开放分区更能体现出产品的优异性能,但Graphcore还是选择在开放和封闭分区都进行了提交。
测试结果体现了Graphcore系统的优异性能,即使在具有限制规格的开箱即用的封闭分区上也是如此。更令人瞩目的是开放分区结果,Graphcore能够在其中优化部署,以充分利用IPU和系统功能。这更贴近真实应用,支持客户可以不断提升其系统性能。
“每美元性能”指标
MLPerf被称为比较基准,实际上进行直接比较可能很复杂。从相对简单的硅片到有着昂贵存储的复杂堆栈式芯片,如今的处理器和系统架构可谓千差万别。从“每美元性能”角度来看,往往最能够说明问题。
Graphcore的IPU-POD16是一个5U的系统,标价149,995美元。如前所述,它由4个IPU-M2000加速器以及行业标准主机服务器构成。每个IPU-M2000由4个IPU处理器构成。MLPerf中使用的NVIDIA DGX-A100 640GB是一个6U机盒,标价约为300,000美元(基于市场情报和公布的经销商定价),有8个DGX A100芯片。IPU-POD16的价格是它的一半。在这个系统中,IPU-M2000的价格和一个DGX A100 80GB的价格是一样的,或者在更细的层次上,一个IPU的价格是它的四分之一。
在MLPerf比较分析中,Graphcore采用了严格监管的封闭分区的结果,并针对系统价格对其进行了归一化。对于ResNet-50和BERT,很明显Graphcore系统提供了比NVIDIA产品更好的每美元性能。在IPU-POD16上进行ResNet-50训练的情况下,Graphcore的每美元性能是NVIDIA的1.6倍。在BERT上,Graphcore的每美元性能是NVIDIA的1.3倍。Graphcore系统的经济性可以更好地帮助客户实现其AI计算目标,同时,由于IPU专为AI构建的架构特点,Graphcore系统还可以解锁下一代模型和技术。
Graphcore高级副总裁兼中国区总经理卢涛表示:“首次提交MLPerf就获得如此出色的成绩,我们感到非常自豪。此次测试还会带给Graphcore客户更多价值,因为我们在准备阶段所做的所有改进和优化都会反馈到Graphcore软件栈中。全球范围内的Graphcore用户都会从MLPerf测试中受益匪浅,不仅局限于BERT和ResNet-50模型。我们将继续参与包括训练和推理在内的MLPerf测试,为追求更优性能、更大规模和添加更多模型,贡献Graphcore的所有智慧和力量。”